Posted by Anita on June 5th, 2008 — in audio features, contextual features, milestones, videos
Yesterday I set up the MusicBox to animate transitions as you enable or disable features. I took a short video of this: it starts with no features enabled, and I go through each feature (or set of features; they are enabled in blocks together, like all allmusic.com tags at once), adding it, and you can see the shape of the musical space change as those features’ influence are added and subtracted.
The program is recalculating the space after every change, by performing a new principal components analysis, and then displaying all the tracks in their new locations.
Click image to view QuickTime movie (14.2 MB).
The animation isn’t perfect, specifically because the scale can change dramatically when feature sets are changed, and I didn’t interpolate that properly (it’s too complicated given the way I’ve written my code… blech, lesson learned). But it still gives a good sense of how each song is moving throughout the changing space.
No Comments »
Posted by Anita on April 20th, 2008 — in audio features, contextual features, screenshots
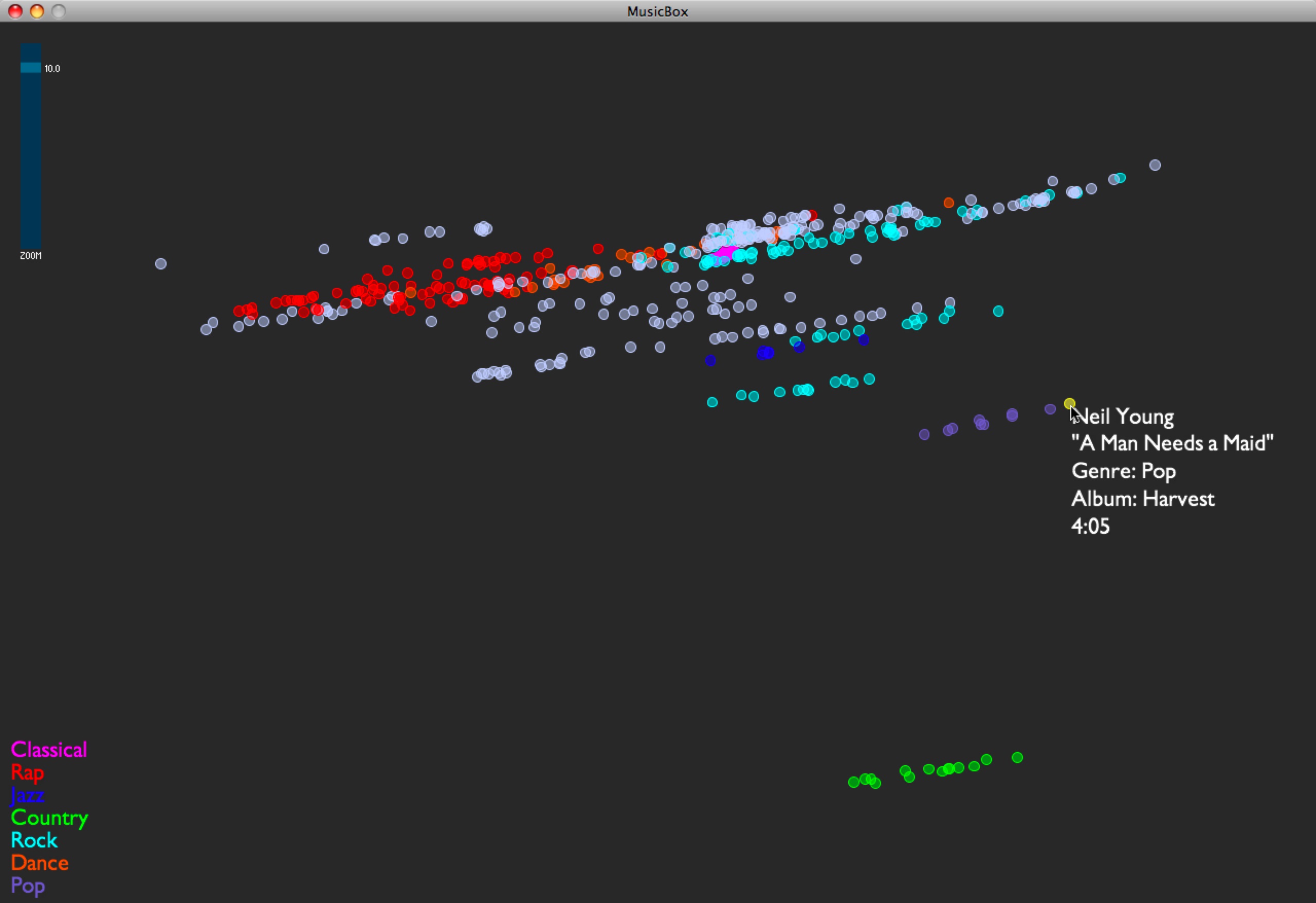
I implemented the first set of contextual data for my test set of music. I’m grabbing moods off of allmusic.com. These are descriptors like “spooky”, “lively”, or “epic”, which are usually listed per album. I’m incorporating these features into the PCA by treating each descriptor as a separate feature, giving each song with the given descriptor a “1”, and all others a “0”. These contextual data are being added into the model that already has audio-based data.
As expected, this stratifies the whole data set, and is an interesting way of separating out the albums… those albums with the same sets of mood tags appear in a stripe across the space, and their position in the stripe comes from the audio features. If I had to guess what the audio feature separation means here, I’d say it’s distributing music on a spectrum of edgier, more bursty sounds (on the left in this visual representation) to smoother, softer sounds (on the right). I am guessing this purely from inspection.
Here are some examples:
- I see a stripe of this album: Backstreet Boys — “Black & Blue”. It moves from “Shining Star” (click to listen; you need Windows Media Player) on the edgy side, to “How Did I Fall In Love With You“ (click to listen IF YOU DARE; you need Windows Media Player) on the smooth side.
- I see a stripe of this album: The Beatles — “Sgt. Pepper’s Lonely Hearts Club Band”. It moves from “Getting Better” on the edgy side, to “Lovely Rita” in the middle, to “A Day In the Life” on the smooth side.
- I see a stripe of this album: 10,000 Maniacs — “Our Time in Eden”. It moves from “Candy Everyone Wants“ on the edgy side, to “How You’ve Grown“ on the smooth side.
Also, Busta Rhymes’ smoothest piece in the test set, “Hot Fudge”, is way less smooth than the Beatles’ edgiest piece.
No Comments »
Posted by Anita on April 15th, 2008 — in audio features, feedback
My newest problem is one that I knew I’d come across eventually: What do I do with songs that have missing data? This most recently came up when I was adapting Thomas Lidy’s rhythm feature code… It couldn’t open some of the MP3s in my test set, so I have no rhythm feature data for those songs. Lacking a better idea, I just gave them the mean values of all the other songs. But this doesn’t seem right… I can’t really give them any value. But if I don’t give them any values, the PCA can’t process these tracks anymore; I can’t put them in the space at all.
So, not sure what to do about these songs. Anyone have any suggestions?
3 Comments »
Posted by Anita on April 15th, 2008 — in audio features, screenshots
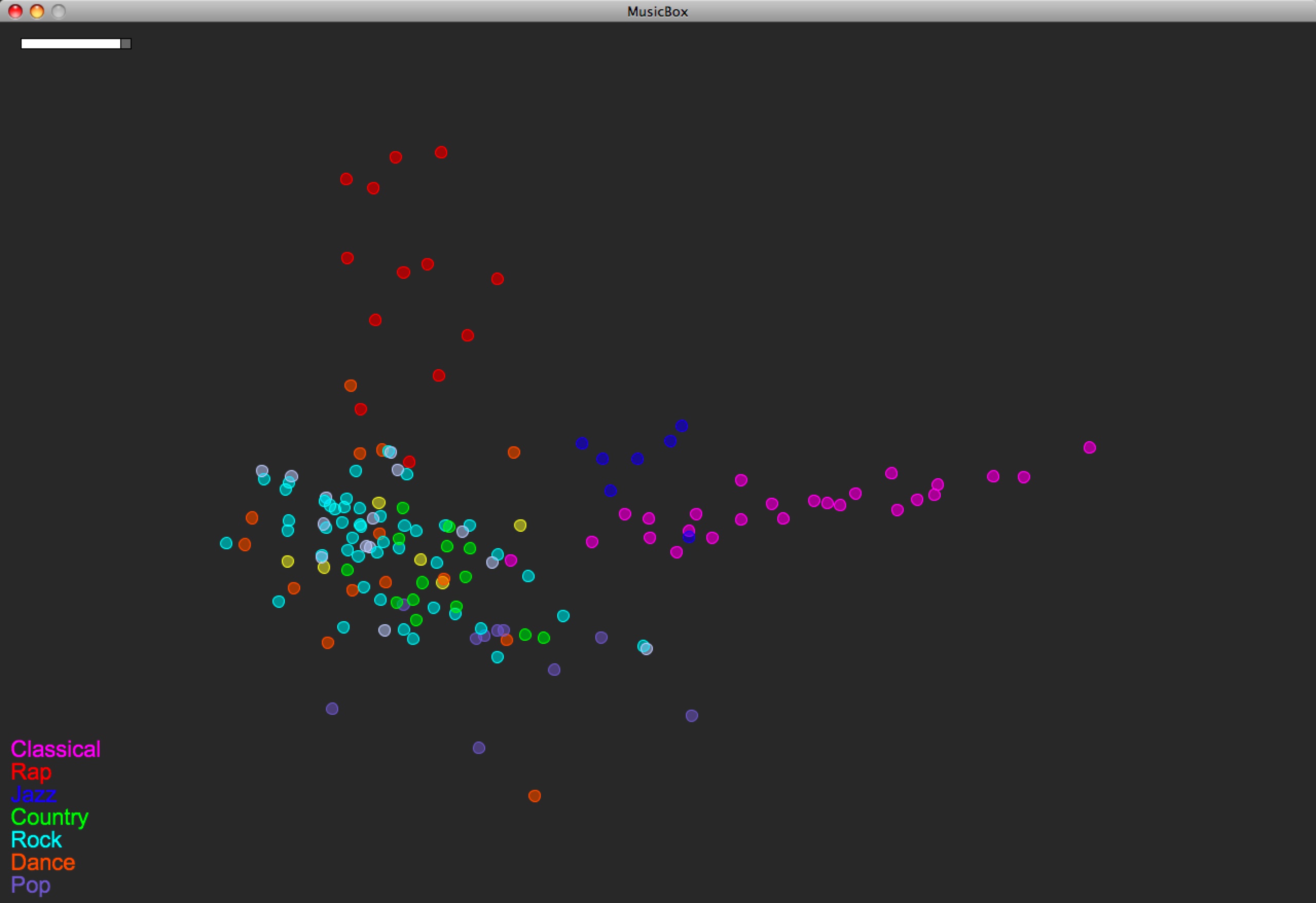
I was able to add some rhythm features to the model. I’m using Thomas Lidy and Andreas Rauber’s Rhythm Histograms (RH), summarizing each histogram (one histogram per song) with four features: mean, median, standard deviation, and (at Thomas’s recommendation) kurtosis. Here’s how the map of the same music library looks now:
You can compare with the last version, before RH features were used:
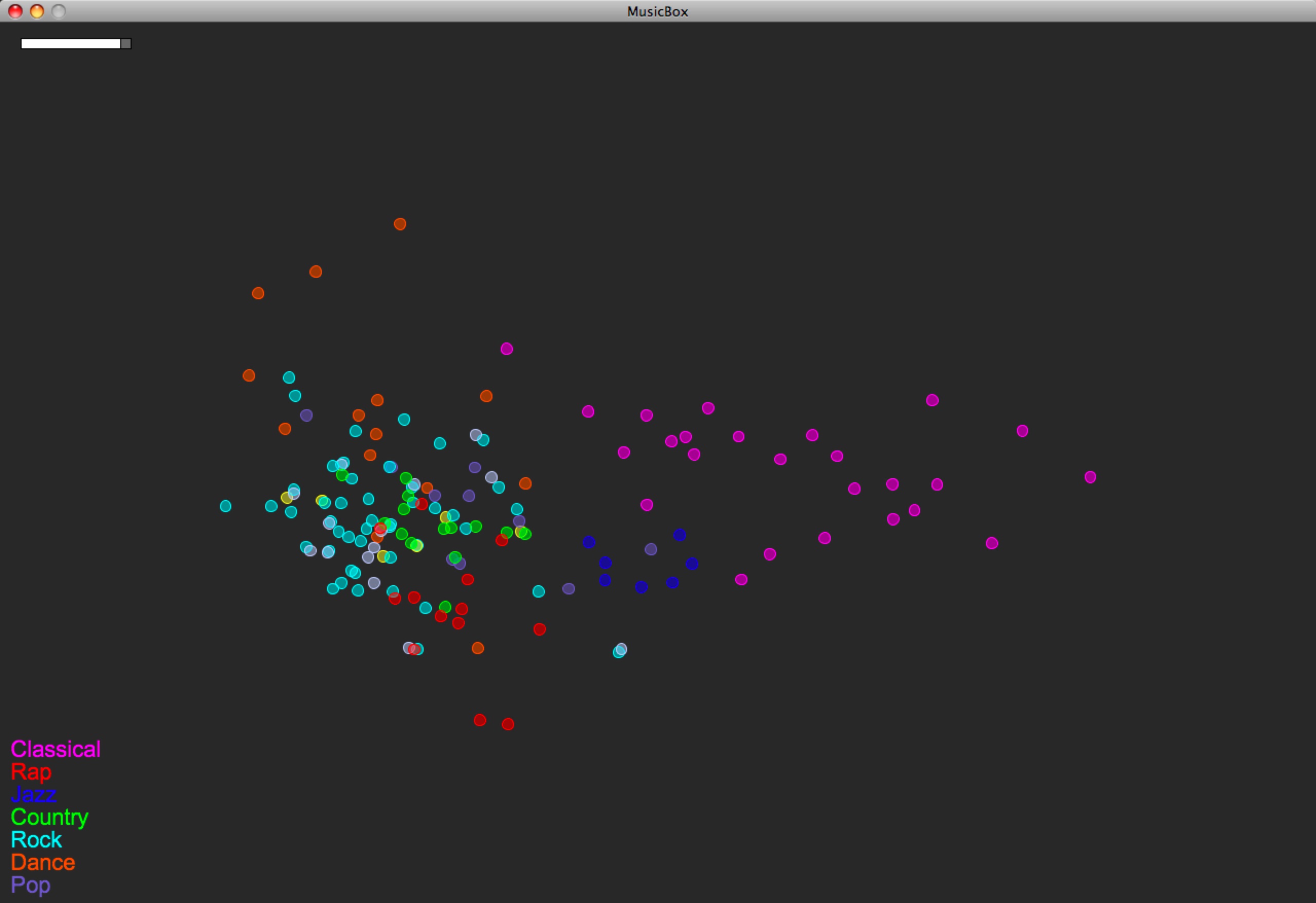
Unfortunately the Rhythm Histogram code couldn’t open my classical music, so you have to disregard that data (to which I gave the mean value of the rest of the songs’ RH data).
So the main thing that happened here is that the rap music popped out. And perhaps a wee bit the jazz.
1 Comment »
Posted by Anita on February 4th, 2008 — in audio features, definitions, feedback
I’m getting more into my coding, and now am trying to answer the question, “What is a feature?” Specifically, what are the features that I can glean from the audio to get a meaningful distinction between one song and the next, and what is the general description of this thing I call a “feature”.
My project is not intended to be focused on figuring out or implementing these features; I am focused on bringing them together into a navigable representation. But in the design of the Feature class I’m finding myself wondering:
- Do features operate at the song level, or at the section level? I should have the ability to deal with either type, but then, I am sometimes mapping song sections, and sometimes whole songs. What do I show to the user in the interface if I’m only really mapping a section of a song?
- Should I try to choose one section to be representative of the piece as a whole, and just do my analysis on that section?
- What are the must-have features people have already written code for, that can be easily adapted and plugged in to my engine?
- What kind of rhythm-based features can I pull out? (I mention this because I am sorely lacking in the rhythm arena.)
I will start with features like this (for each track):
- number of sections
- number of types of sections (counted by timbre type)
- number of types of sections (counted by pitch pattern type)
- mode of timbres
- mean level of specific timbre coefficients (coefficients shown visually at the bottom of this page)
- tempo
- mean loudness (or max, maybe)
- confidence level of autotag assignment with tag1, tag2, tag3, etc… (multiple features here)
- frequency of appearance of tag assignment with tagA, tagB, tagC, etc… (multiple features here)
- time signature
- time signature stability
- track duration
(Note that, right now, I am not talking about similarity measures for pairs of songs, but rather quantifiable measures for one song at a time. I’ll deal with similarity later.)
4 Comments »